- Se incorporó
- 15 Enero 2004
- Mensajes
- 11.998
Distintas herramientas que permiten controlar el estado de tu plataforma, desde pings sencillos hasta simulación de logueo en una página web, pasando por el control de espacio en disco, cpu y memoria.
Nagios
Nagios Core: Gratis.
Nagios Xi: Pagado.
Nagios - The Industry Standard in IT Infrastructure Monitoring
http://www.nagios.org/

Icinga
Derivó de Nagios. Es gratis. Como buen fork es muy similar a nagios en su concepción pero se han ido distanciando un poco.
https://www.icinga.org/

Foglight
Es una suite de Quest, que ahora es de dell. Hay componentes que se instalan sobre Windows Server y en poco tiempo puedes estar controlando a punta de ping y snmp toda tu plataforma. Es caro.
http://www.quest.com/foglight/

System Center Operations Manager
System Center es una suite de productos de Microsoft que tienen como objetivo controlar tus plataformas, haciendo hincapié (obviamente) en productos y servicios de Microsoft. El componente Operations Manager monitorea a nivel de ping, de snmp, de WMI (protocolo de Windows). Para monitorear servidores Microsoft es excelente, pero para monitorear Linux es pésimo. Si tu plataforma tiene mayoritariamente servicios y productos Microsoft, como Active Directory de Microsoft, Exchange, Sharepoint, etc, System Center Operations Manager es tu mejor opción si es que tienes las lukas. Es pagado.
http://technet.microsoft.com/es-es/library/hh205987.aspx

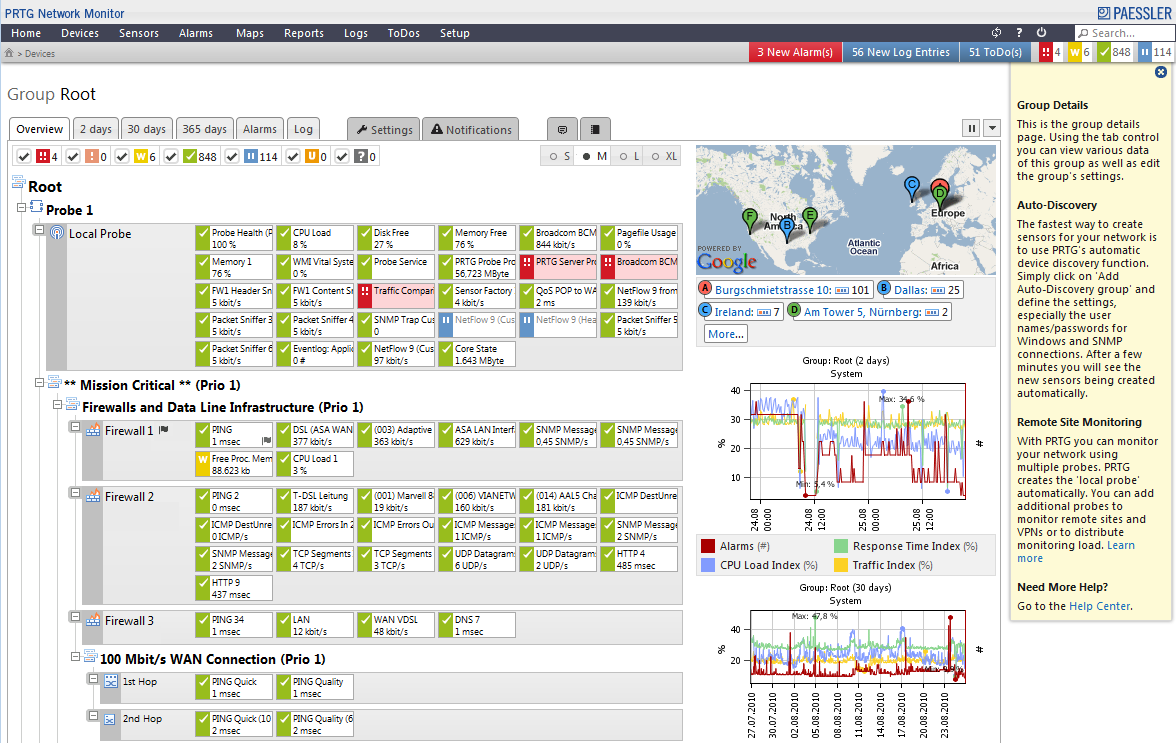
PRTG
Permite desplegar monitoreo por SNMP y PING, además integra mibs especializados para distintos tipos de plataformas y aplicaciones como VMware, Hyper-V, SQL, Oracle, etc.. Tiene la ventaja de ser muy flexible y extremadamente facil de desplegar.
Es de pago y tiene versión trial.
http://www.paessler.com
Newrelic
http://newrelic.com/
Newrelic se corre como un servicio en tus máquinas, y va reportando periódicamente a un servicio Cloud. La versión básica es gratis.
El panel de Newrelic cumple dos funciones: monitorear tus máquinas y monitorear tus aplicaciones. Esta es una relación muchos a muchos: en un panel tienes tus máquinas (y cada una dice abajo cuales de tus apps está corriendo) y en otro panel tienes tus aplicaciones, y cada una puede estar corriendo en N máquinas.
En la vista particular de una máquina tienes información de la carga y los procesos más pesados.

La foto que te muestra es de los últimos 30 minutos. Puedes cambiar ese tiempo para mostrar, en cambio, una hora, tres, seis o hasta 12 horas, y puedes mover ese intervalo para ver por ejemplo la carga entre las 15 y las 18 horas del día anterior.
Además del demonio de sistema, Newrelic tiene librerías para la mayoría de los lenguajes de desarrollo: PHP, Python, Ruby, JAVA, .NET y Node. Con eso se perfila tu aplicación. En la pestaña de Aplicaciones puedes ver cuales son las transacciones que más peticiones generan, o que más tiempo consumen. Puedes ver los últimos errores o medir qué tablas se llevan más pega en la BBDD

Ya que te muestra en qué máquinas está corriendo una cierta aplicación, podrías sacar mediciones tan reveladoras como:
- Máquina 1 está al 80% de carga, está recibiendo 50 peticiones por segundo y corre apache
- Máquina 2 está al 5% de carga, recibe 200 peticiones por segundo y corre nginx
(El ejemplo es real, hice ese ejercicio el 2012 para hacer lobby a favor de nginx en mi pega)
Newrelic tiene plugins para casi cualquier servicio que se les ocurra, pero estos plugins son desarrollados por los respectivos proveedores y a veces no tienen mucho gráfico o no sirven de nada. De todas maneras les comento que he probado los plugins de mysql, amazon aws, postgres, php-fpm, mongodb y nginx. Todos funcionan y algunos se pueden integrar con las alertas nativas de Newrelic.
y algunos se pueden integrar con las alertas nativas de Newrelic.

Justamente esa es otra cosa bien útil que tiene Newrelic: un sistema de alertas muy granular. Puedes definir grupos de alertas y grupos de usuarios, y decidir qué eventos gatillan cierta alerta a cierto grupo. Por ejemplo
- Si el HDD de una máquina está al 90% de capacidad, alerta al grupo de sistemas
- Si el porcentaje de errores de una app sube del 5%, alerta al grupo de desarrolladores
- Si el ping deja de responder por un minuto, alerta a todos los weones que se cayó el sitio
Las alertas se pueden gatillas por correo, pero también puedes mandarlas a una cola de Amazon SQS, a un SMS (no funca en Chile), a un sistema de ticketing como Zendesk o a un cliente de Chat como Hipchat.
Observium.
http://www.observium.org/
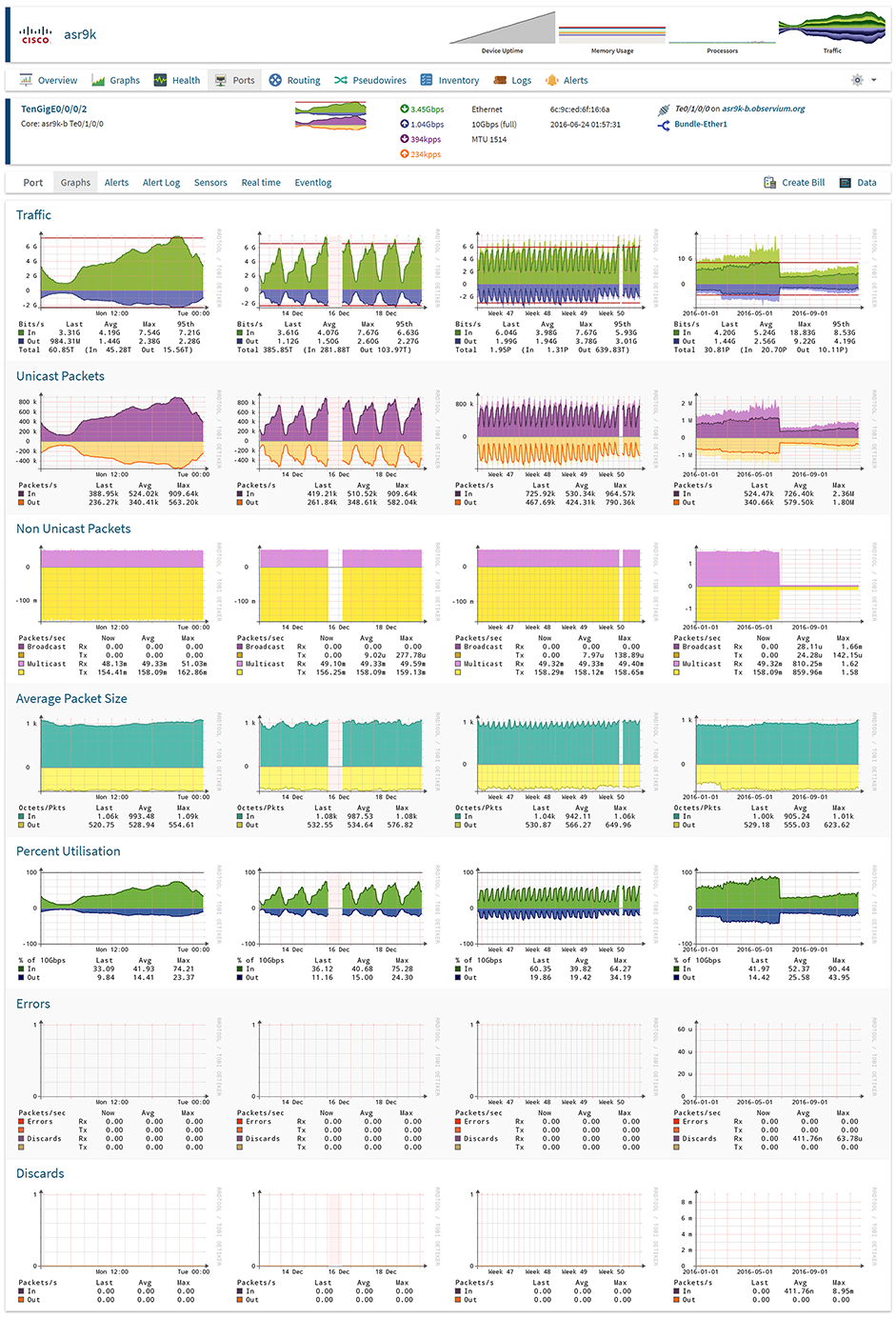
Permite monitorear en tiempo real dispositivos de red como Switchs y routers al nivel de puertas mediante el protocolo SNMP, además de controlar servidores también vía SNMP. Tiene opción gratuita y de pago.
ELK stack
https://www.elastic.co/
ELK stack es un diminutivo para Elasticsearch - Logstash - Kibana, y permite reunir información de muchos lados y de distintos tipos para mostrar gráficas como los que puse arriba en un solo panel centralizado.
Así por ejemplo puedes, tal como se ve arriba, importar los access_logs y error_logs de apache o nginx, o estadísticas de máquinas como load o uso de disco, o todo lo que se logea hacia systemd por ejemplo.
En el caso de arriba, en la pega también importamos eventos, como los de la centralita de teléfono: cada llamada entrante o saliente la logea, o bien, cuando ocurre algo (se envía un correo por ejemplo), se crea un evento con ciertos parámetros mediante los cuales filtro.
Hay dos variantes: la gratuita y la pagada. La pagada incorpora elementos avanzados como cuentas de usuario y otras cosas de forma fácil, se puede hacer todo con plugins gratuitos pero muchos son un culo de instalar.
La gracia de ELK stack es que permite escalar con facilidad, gracias a que puedes definir N nodos de ElasticSearch, Logstash o Kibana (si es que hace falta), aunque sugiero investigar antes de meterse del todo, ya que el setup inicial puede ser complicado. Yo estuve 2 semanas de lleno instalando todo, pero estamos conformes con el resultado. Hoy mismo hubo un problema con un backbone entre dos datacenters y lo detectamos al tiro:

Nagios
Nagios Core: Gratis.
Nagios Xi: Pagado.
Nagios - The Industry Standard in IT Infrastructure Monitoring
http://www.nagios.org/
Icinga
Derivó de Nagios. Es gratis. Como buen fork es muy similar a nagios en su concepción pero se han ido distanciando un poco.
https://www.icinga.org/
Foglight
Es una suite de Quest, que ahora es de dell. Hay componentes que se instalan sobre Windows Server y en poco tiempo puedes estar controlando a punta de ping y snmp toda tu plataforma. Es caro.
http://www.quest.com/foglight/
System Center Operations Manager
System Center es una suite de productos de Microsoft que tienen como objetivo controlar tus plataformas, haciendo hincapié (obviamente) en productos y servicios de Microsoft. El componente Operations Manager monitorea a nivel de ping, de snmp, de WMI (protocolo de Windows). Para monitorear servidores Microsoft es excelente, pero para monitorear Linux es pésimo. Si tu plataforma tiene mayoritariamente servicios y productos Microsoft, como Active Directory de Microsoft, Exchange, Sharepoint, etc, System Center Operations Manager es tu mejor opción si es que tienes las lukas. Es pagado.
http://technet.microsoft.com/es-es/library/hh205987.aspx
PRTG
Permite desplegar monitoreo por SNMP y PING, además integra mibs especializados para distintos tipos de plataformas y aplicaciones como VMware, Hyper-V, SQL, Oracle, etc.. Tiene la ventaja de ser muy flexible y extremadamente facil de desplegar.
Es de pago y tiene versión trial.
http://www.paessler.com
Newrelic
http://newrelic.com/
Newrelic se corre como un servicio en tus máquinas, y va reportando periódicamente a un servicio Cloud. La versión básica es gratis.
El panel de Newrelic cumple dos funciones: monitorear tus máquinas y monitorear tus aplicaciones. Esta es una relación muchos a muchos: en un panel tienes tus máquinas (y cada una dice abajo cuales de tus apps está corriendo) y en otro panel tienes tus aplicaciones, y cada una puede estar corriendo en N máquinas.
En la vista particular de una máquina tienes información de la carga y los procesos más pesados.
La foto que te muestra es de los últimos 30 minutos. Puedes cambiar ese tiempo para mostrar, en cambio, una hora, tres, seis o hasta 12 horas, y puedes mover ese intervalo para ver por ejemplo la carga entre las 15 y las 18 horas del día anterior.
Además del demonio de sistema, Newrelic tiene librerías para la mayoría de los lenguajes de desarrollo: PHP, Python, Ruby, JAVA, .NET y Node. Con eso se perfila tu aplicación. En la pestaña de Aplicaciones puedes ver cuales son las transacciones que más peticiones generan, o que más tiempo consumen. Puedes ver los últimos errores o medir qué tablas se llevan más pega en la BBDD
Ya que te muestra en qué máquinas está corriendo una cierta aplicación, podrías sacar mediciones tan reveladoras como:
- Máquina 1 está al 80% de carga, está recibiendo 50 peticiones por segundo y corre apache
- Máquina 2 está al 5% de carga, recibe 200 peticiones por segundo y corre nginx
(El ejemplo es real, hice ese ejercicio el 2012 para hacer lobby a favor de nginx en mi pega)
Newrelic tiene plugins para casi cualquier servicio que se les ocurra, pero estos plugins son desarrollados por los respectivos proveedores y a veces no tienen mucho gráfico o no sirven de nada. De todas maneras les comento que he probado los plugins de mysql, amazon aws, postgres, php-fpm, mongodb y nginx. Todos funcionan
y algunos se pueden integrar con las alertas nativas de Newrelic.
Justamente esa es otra cosa bien útil que tiene Newrelic: un sistema de alertas muy granular. Puedes definir grupos de alertas y grupos de usuarios, y decidir qué eventos gatillan cierta alerta a cierto grupo. Por ejemplo
- Si el HDD de una máquina está al 90% de capacidad, alerta al grupo de sistemas
- Si el porcentaje de errores de una app sube del 5%, alerta al grupo de desarrolladores
- Si el ping deja de responder por un minuto, alerta a todos los weones que se cayó el sitio
Las alertas se pueden gatillas por correo, pero también puedes mandarlas a una cola de Amazon SQS, a un SMS (no funca en Chile), a un sistema de ticketing como Zendesk o a un cliente de Chat como Hipchat.
Observium.
http://www.observium.org/
Permite monitorear en tiempo real dispositivos de red como Switchs y routers al nivel de puertas mediante el protocolo SNMP, además de controlar servidores también vía SNMP. Tiene opción gratuita y de pago.
ELK stack
https://www.elastic.co/
ELK stack es un diminutivo para Elasticsearch - Logstash - Kibana, y permite reunir información de muchos lados y de distintos tipos para mostrar gráficas como los que puse arriba en un solo panel centralizado.
Así por ejemplo puedes, tal como se ve arriba, importar los access_logs y error_logs de apache o nginx, o estadísticas de máquinas como load o uso de disco, o todo lo que se logea hacia systemd por ejemplo.
En el caso de arriba, en la pega también importamos eventos, como los de la centralita de teléfono: cada llamada entrante o saliente la logea, o bien, cuando ocurre algo (se envía un correo por ejemplo), se crea un evento con ciertos parámetros mediante los cuales filtro.
Hay dos variantes: la gratuita y la pagada. La pagada incorpora elementos avanzados como cuentas de usuario y otras cosas de forma fácil, se puede hacer todo con plugins gratuitos pero muchos son un culo de instalar.
La gracia de ELK stack es que permite escalar con facilidad, gracias a que puedes definir N nodos de ElasticSearch, Logstash o Kibana (si es que hace falta), aunque sugiero investigar antes de meterse del todo, ya que el setup inicial puede ser complicado. Yo estuve 2 semanas de lleno instalando todo, pero estamos conformes con el resultado. Hoy mismo hubo un problema con un backbone entre dos datacenters y lo detectamos al tiro:
Última modificación:

")